
Toward Human Cognition-inspired High-Level Decision Making For Hierarchical Reinforcement Learning Agents
Rousslan Fernand Julien Dossa, Takashi Matsubara
High-level overview
Several studies in the fields of behavioral science, neuroscience, and congitive sciences suggests that the ability of animals and humans to efficiently understand and learn to solve complex tasks is due to their hierarchically structured behavior. As a concrete example, let us consider the task of planning a trip.
The first feature of the human decision process that this work focuses on is the (1) ability simulate and plan the succession of actions to execute, so as to make the trip a reality. The second feature would be the (2) hierarchical structure of the planning process. Indeed, we would usually plan a trip from a higher level of abstraction, for example taking the train from city A in country B to city C in the same country, then _take a plane from city C to city D in country E, and so on. From a lower level perspective, we would also plan the process of buying tickets for transportation, packing luggages, down to in which order and in what specific manner to fold the shirt that goes into the suitcase.
We theorize that this structure of the decision-making process, especially the one at the highest level of abstraction that allows us to understand the steps to solve a given task, then learn the actual action sequences corresponding to the plan.
With this in mind, we set off to enable deep reinforcement learning (Deep RL) agents, and more specifically, hierarchical RL (HRL) agents to leverage such a high-level decision-making process. At the time of this writing, most existing HRL methods do not consider a high-level, abstracted state space in which a correspondingly abstracted decision-making would happen. Indeed, HRL methods often use the full state representation of the task as input to higher level in the hierarchy of policies. This is something we consider as superfluous for a high-level decision-making. Practically speaking, it would be akin to trying to plan the trip while focusing on all the aspects and components (itinerary planning, luggage packing, shirt folding, current location, etc…) to make a decision that only affects luggage packing for example.
The preliminary proposal that constitutes the core of this paper introduces the hierarchical world model (HWM), which is geared to capture the dynamics of the task into a hierarchically structured process. By doing so, the HWM would provide state spaces at different level of abstraction. Then, integrating the HWM with the HRL framework would produce an approximation of the aforementioned high-level decision-making process derived from humans.
More specifically, let us consider the Four Rooms task, as illustrated at layer (a) in the figure below. In this representation task of the HRL paradigm, the agent denoted as the red arrow has to traverse the rooms of the maze to reach the exit, which is denoted as the green tile. While seemingly trivial for humans, the complexity of this task for (H)RL agents can grow exponentially as the maze becomes more complex.
From the human perspective, the intuitive way to solve this would be as follows: from a higher level perspective, we set off to navigate the avatar (red arrow) from the room it was initialized to the room that contains the goal. Once that plan is defined, we progressively go to lower level of abstraction. The next step would thus focus on moving the agent in the current room toward the door that leads closer to the room containing the goal tile, and so on.
The proposed model aims to provide a temporally abstract state as illustrated in layer (c) of the figure below, where the high-level policy of an HRL agent will focus on guiding the overall agent toward a specific room. Meanwhile, the low-level policy would instead focus on navigating the current room the overall agent is located in, to reach the location instructed by the high-level.
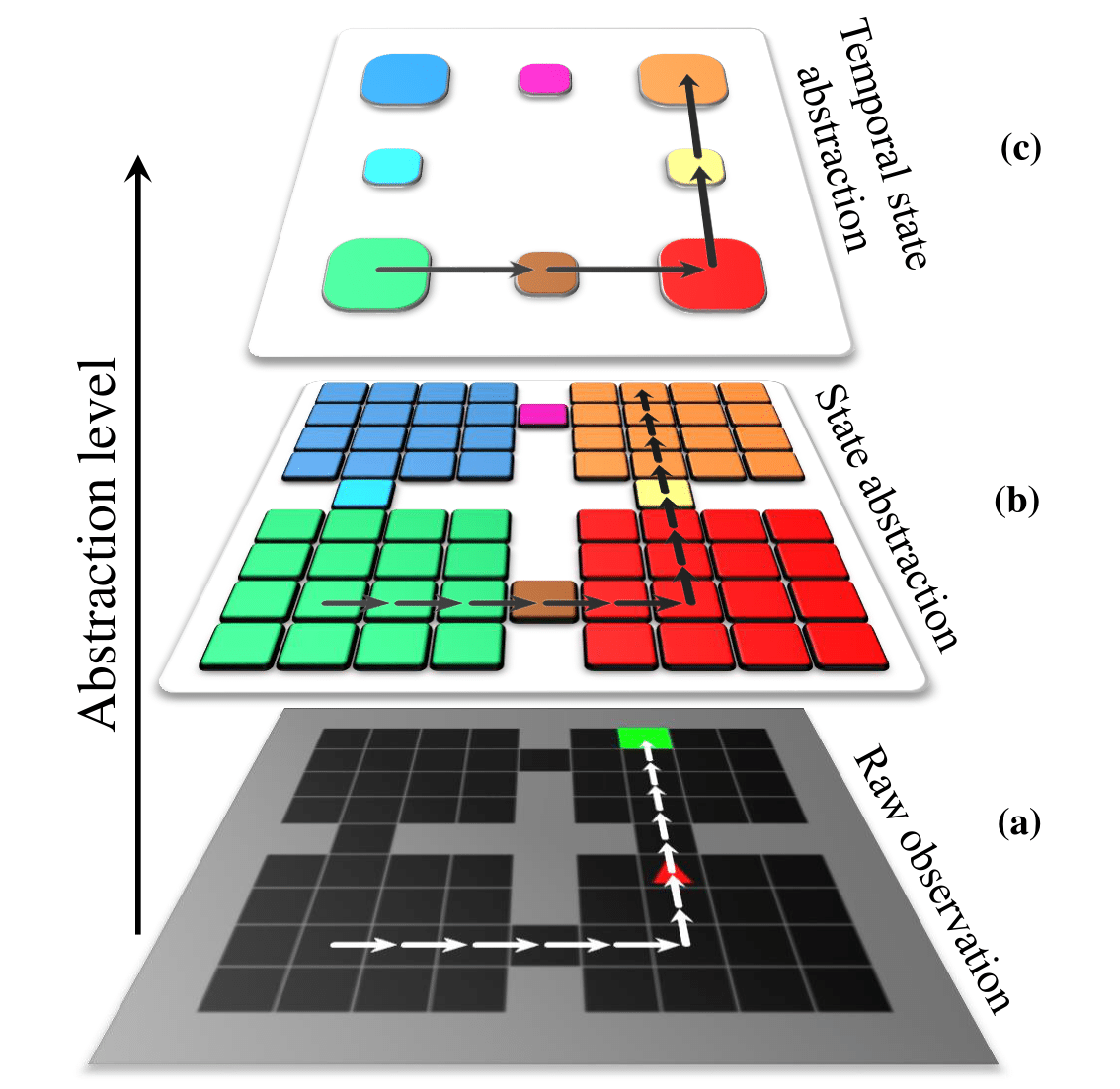
As the HWM augment HRL agent learns, we expect it to explore in a more principled way, owing to the guidance of the high-level policy that acts at a correspondingly abstract level. This would then make the exploration of the overall agent exhaust the state space faster than conventional (H)RL methods, thus aligning with human intuition of solving this task, and more generally, with our high-level decision-making process.
Preliminary works and previous publications
In this paper, we propose a hierarchically structured world model that would separate the internal state of the system (task) into two-level hierarchy of latent variables. The low-level latent variables is expected to encode fast-changing elements of a given RL task, while the high-level of the hierarchy would encode slowly changing elements. The latter are approximated using variational temporal abstraction.
Preliminary results were also presented at 2021 Non Linear Science Workshop with the following extended summary:
Leave a comment